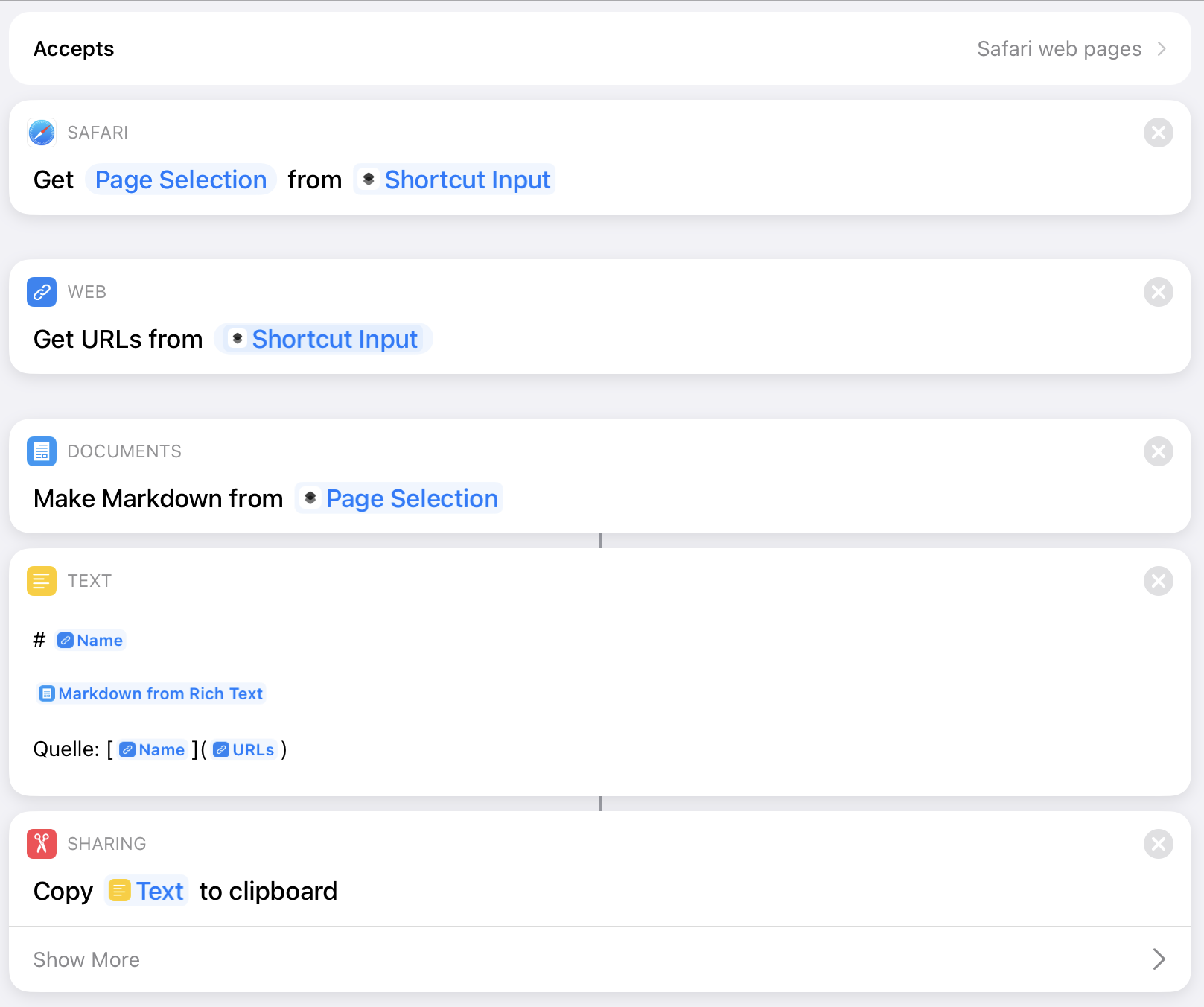
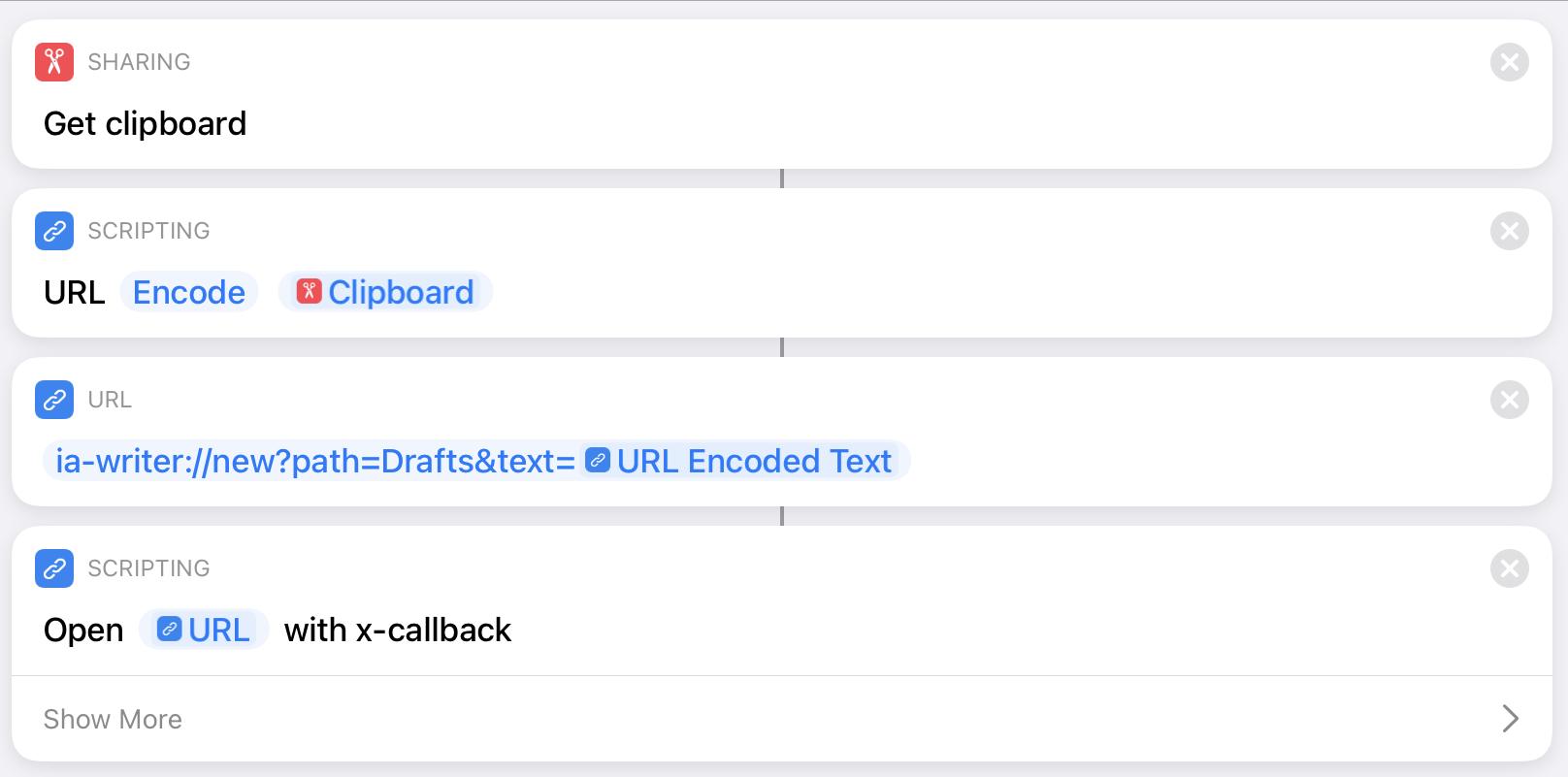
The usage of an RSS reader app represents a significant part of my daily media diet. I’ve been through “all of them”, switched back and forth between the different apps. Satisfied, but never fully happy with my choices.
I briefly used Lire for some time a couple of years ago, became unhappy with some random detail, and moved on to one of the “usual suspects”: Reeder, Fiery Feeds, Unread.
Out of frustration over some aspects of the mentioned alternatives, I came back to Lire some months ago. For the larger part of the last year, I have been using Lire exclusively for my feed reading. The app undoubtedly has its ups (many) and downs (few), but overall the state of the app has been a very welcome surprise to me.
Without further ado, what I really like about Lire is the reading experience. The text parser keeps impressing me. It hands down delivers the best text processing results I have ever seen in any RSS reeder app. In the few cases where I submitted a request for improvement to the developer of Lire, the improvement was implemented and rolled out in less than a day!
I do the majority of my feed reading on my 12.9 iPad Pro, where I have the choice to read the text in a three-pane, two-pane, or full-screen layout. Personally, I use the three-pane layout for quickly browsing through a list of articles, switch to the two-pane layout for articles that I want to focus on, and expand to the full-screen layout mostly for articles with many pictures.
Lire even goes the extra mile to also parse the text of a linked post, no forwarding to a website (as for many other apps) required. That’s the attention to detail that really makes a difference.
Tables are rendered cleanly and (yay!) footnotes appear as little pop-ups, bigfoot style.
Lire supports a large selection of RSS aggregator services, but can (unlike, e.g. Reeder) only sync to one service at a time. There are apps that sync and cache feed text faster than Lire, but not by a meaningful amount.
It is possible to inline frames in the reading pane. If the inlining is deactivated, videos will immediately play full-screen (this is one of my favorite features).
The overall product quality of the app is great. Lire is very stable and crashes are very rare, especially in comparison to some direct competitors.
The only minor issue that I still have with Lire is the design. Maybe it is just me, but the available app icons feel like they have been rushed out of the door without getting the polish they deserve for representing such a capable app.
I don‘t expect a masterpiece akin to the white-star-on-red-background „classic red“ icon available in Reeder, but maybe a little bit of originality wouldn‘t hurt.
Lire offers three light and three dark themes and supports automatic theme switching controlled by the system settings. The available themes are okay-ish, but in my opinion lack a bit of “personality”. Especially the light themes suffer from too much greyscale, in my personal opinion.
In summary: for me, Lire already represents an almost unbeatable package for RSS reading. A fresh coat of paint and — one can dream — the ability to use custom fonts in the article view would make Lire an even stronger recommendation.